
Actions
Issue #6121
closed
Syncs of very large repositories take longer than Pulp 2
Start date:
Due date:
Estimated time:
Severity:
2. Medium
Version:
Platform Release:
OS:
Triaged:
Yes
Groomed:
No
Sprint Candidate:
No
Tags:
Sprint:
Sprint 67
Quarter:
Description
A Pulp 2 immediate-mode sync of 150,000 files using this repository [0] takes 37.5 minutes
With Pulp 3, the same sync takes about 3x as long (about 2 hours).
An on_demand sync of the same repo in Pulp 3 takes about 90 minutes, still much longer than Pulp 2.
The first 50k files seem sync roughly as fast as they do for Pulp 2, but once the number grows higher to progress starts being made very very noticeably slower than at the beginning.
[0] http://quartet.usersys.redhat.com/pub/fake-repos/very_large_file_150k/
Files
| sync-file-perf-cprofile.txt (195 KB) sync-file-perf-cprofile.txt | The output is ordered by cumtime | ||
| sync-file-perf-cprofile.out (244 KB) sync-file-perf-cprofile.out | gprof2dot -f pstats sync-file-perf-cprofile.out | dot -Tpng -o output.png | ||
| feb28-fix.out (240 KB) feb28-fix.out | |||
| feb28-fix.png (1.04 MB) feb28-fix.png | |||
| feb28-master.png (585 KB) feb28-master.png | |||
| feb28-master.out (239 KB) feb28-master.out |
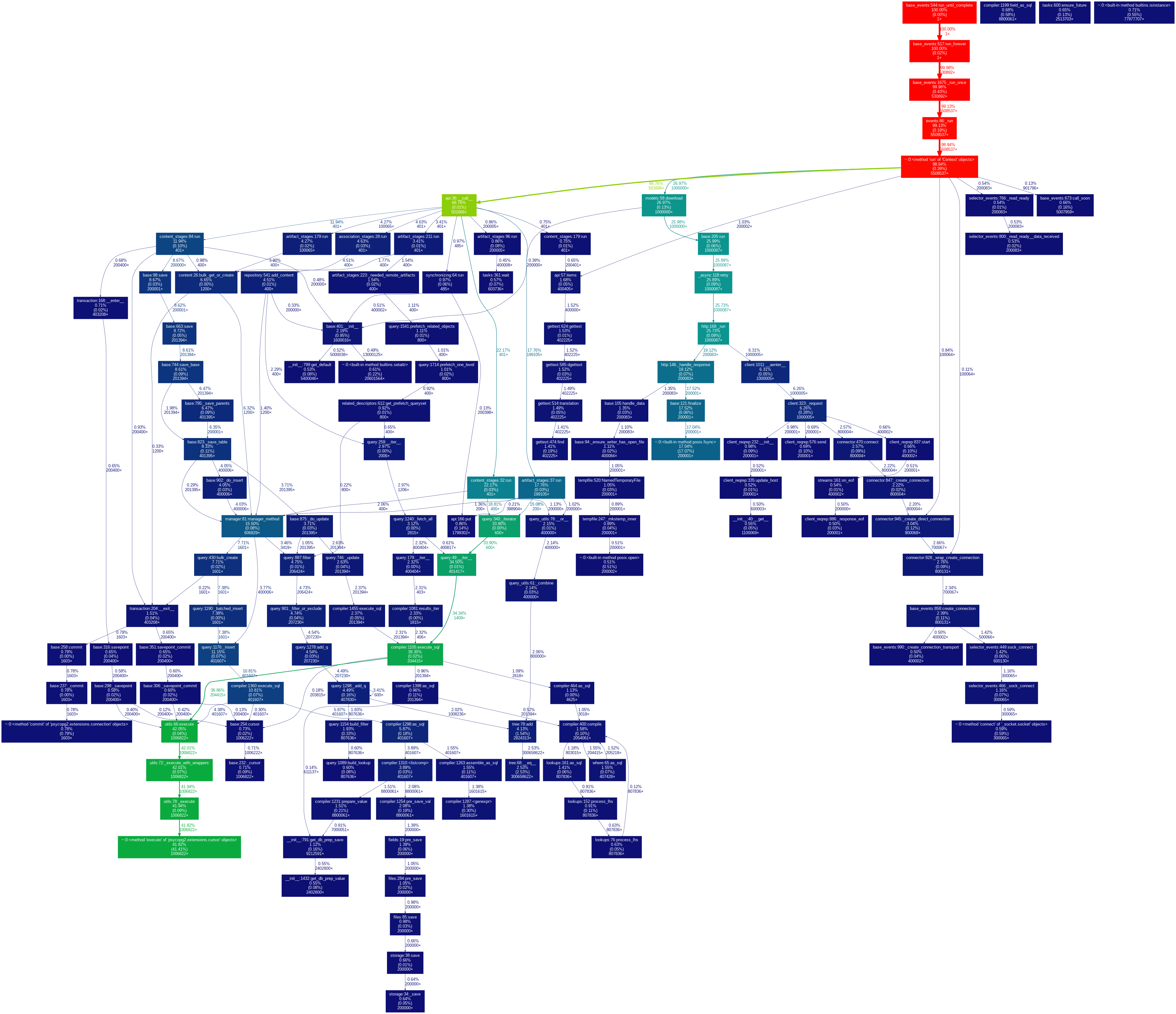{kind=link}
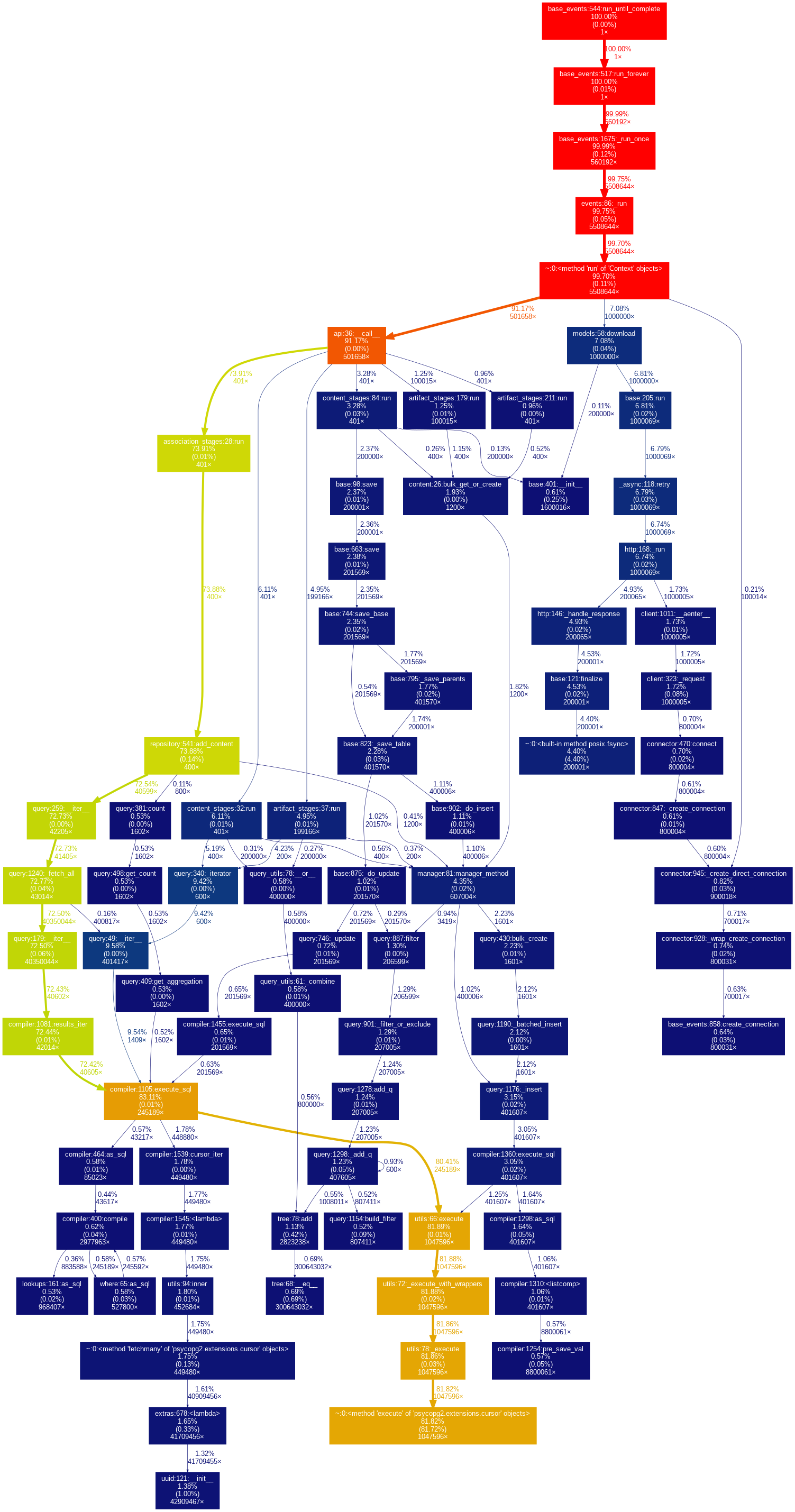{kind=link}
Related issues
Actions
Fetch excluded content directly from the database
fixes #6121 https://pulp.plan.io/issues/6121