Refactor #2143
closed
Evaluate applicability solutions for 3.0
Description
A strong relational model has potential to support moving back to on-demand applicability calculation. The report-ready data may not longer be necessary. After the RPM modeling (which includes errata) is complete, we need to populate a database and test whether applicability can be implemented using queries with acceptable performance.
Files
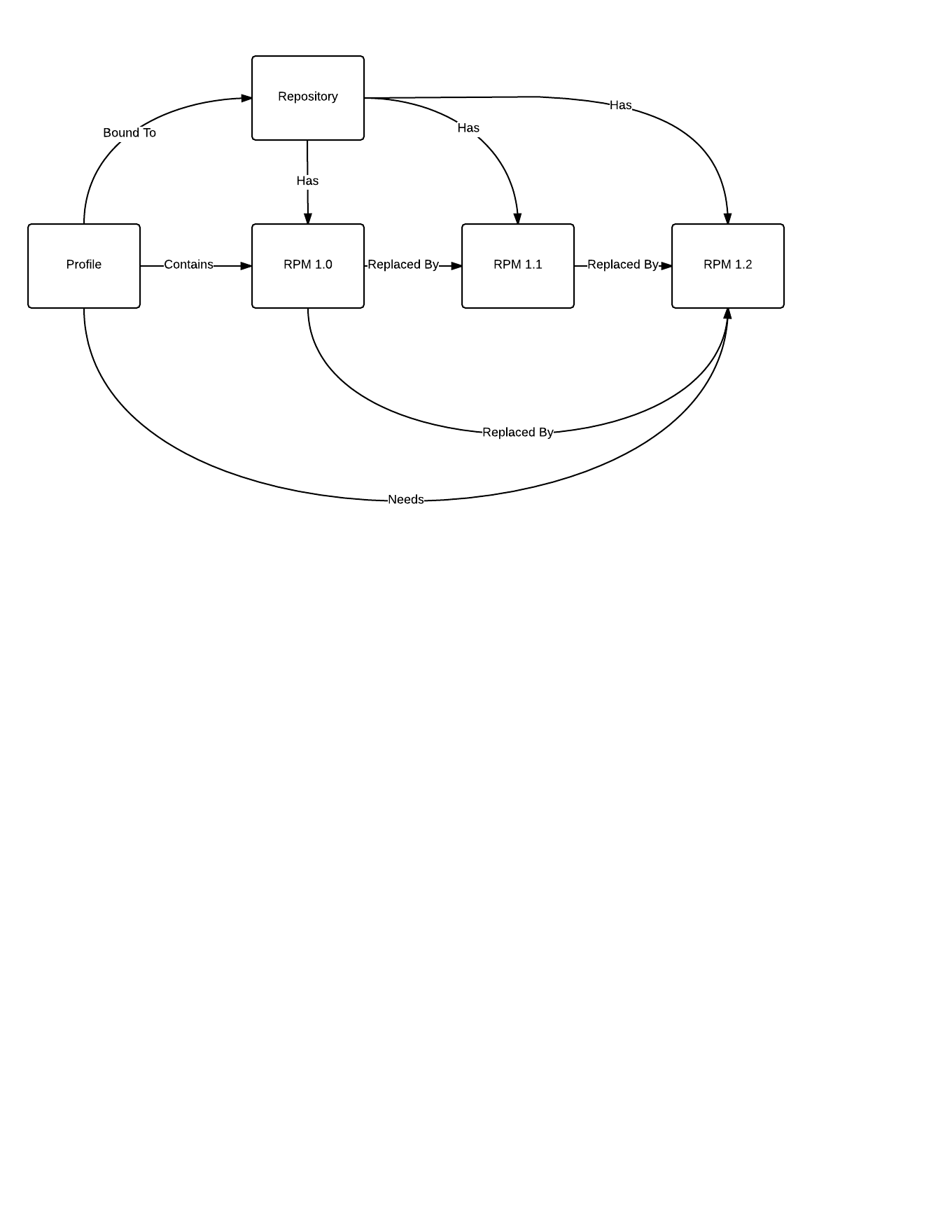
I'm attaching a graph I made some time ago showing the relationships that need to be traversed, at least for RPM content, to figure out what content is applicable. It would likely be very similar for other content, with just a different version comparison algorithm.
It may be helpful to reference this graph when thinking about how to create queries. Ping me if explanation would be useful.
The "Needs" relationship along the bottom is the query result.
I think the query roughly boils down to: show me content where for a given system profile:
- the content is in a repository that the profile is also bound to
- the content replaces some other content that is already part of the profile
- the content is not replaced by anything else
When considering how to implement this in Pulp 3.0 it is worth looking at what Spacewalk does to calculate errata/package applicability. Spacewalk is only concerned with two content types: RPM packages and Errata. Errata are composed of packages. So we can really just discuss packages. Spacewalk takes a list of packages (profile) for a particular consumer and determines which packages in all repositories the consumer is subscribed to have a version greater than the version of the same package in the consumer profile. This calculation is performed using a stored procedure[0] that is able to take advantage of a custom type used to represent NVRA[1]. The custom NVRA type defines how NVRAs should be compared. The stored procedure computes which errata/packages are actually applicable.
Plugin writers should be able to define custom types for PostreSQL as well as stored procedures that can be used to perform applicability calculations.
Pulp's Plugin API should provide
- A mechanism for adding new types and stored procedures to the database.
- A basic Profiler interface that plugin writers can implement. The implementation would most likely run a stored procedure.
Pulp should provide REST APIs for:
- Uploading unit profiles that consist of two lists: installed units, associated repositories.
- Calculating applicability for a particular unit profile.
- Calculating applicability for all unit profiles associated with a repository.
- Retreiving applicability for a particular unit profile and content type.
[0] https://github.com/spacewalkproject/spacewalk/blob/SPACEWALK-2.5/schema/spacewalk/postgres/packages/rhn_server.pkb#L662-L696
[1] https://github.com/spacewalkproject/spacewalk/blob/SPACEWALK-2.5/schema/spacewalk/postgres/class/evr_t.sql
Generally all of this sounds good. +1 to using a stored procedure and moving the applicability calculation into the database.
One thing I contemplate is if we will have to "manage" stored procedures or accept stored procedures written by plugin writers. I was hoping we could write the one or two stored procedures which could be reused for all content types. Somehow we need the plugin author to give us everything that stored procedure would need on the model definition.
If we did have a stored procedure per content type, how would Django support that such that they could be installed with the Django migrations system?
- Related to Task #2450: Create a plan for applicability calculation implementation added
- Status changed from NEW to CLOSED - WONTFIX
Applicability is out of scope for Pulp 3. It's done in Katello.
Also available in: Atom
PDF


{kind=link}