A little more background - and some ideas for how we can potentially improve Pulp.
Some testing was done that showed that Pulp was spiking high enough to run out of memory even on a box with >11gb of RAM running only Pulp 3 + Katello, which is a problem.
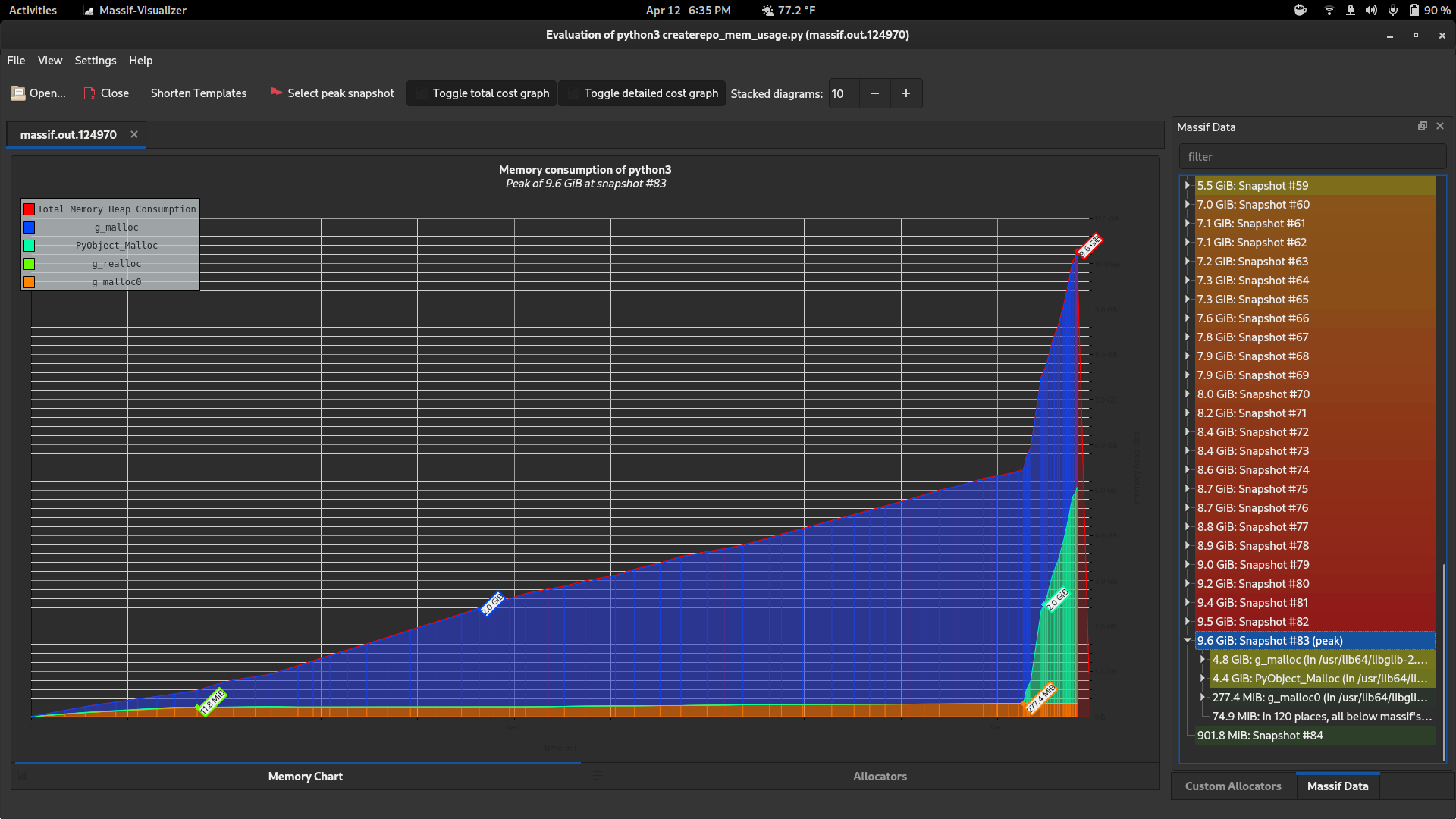
I ran some tests which showed that the memory usage of createrepo_c alone is about what we would expect. The memory cost of processing a repository is roughly the (decompressed) size of the metadata - larger metadata, more memory consumption. I used the OL7 repository for testing since it's the largest one I've seen so far, larger even than RHEL7.
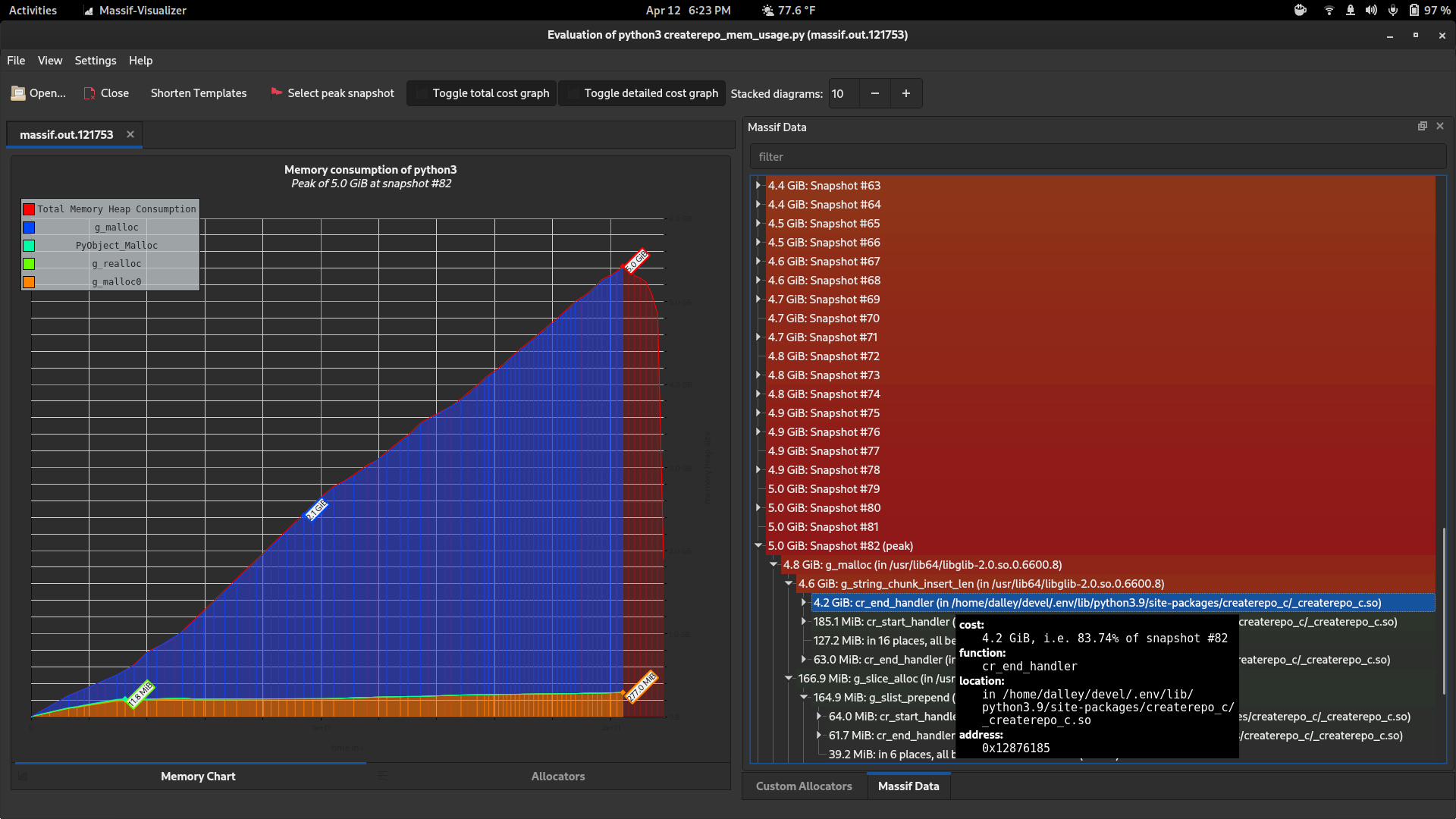
This is a baseline result using a script that just parses the repo metadata into a dict like we do, and nothing else. It peaks at around 5.1gb of memory, which is a bit bigger than the actual metadata (other.xml alone is 4.2gb)
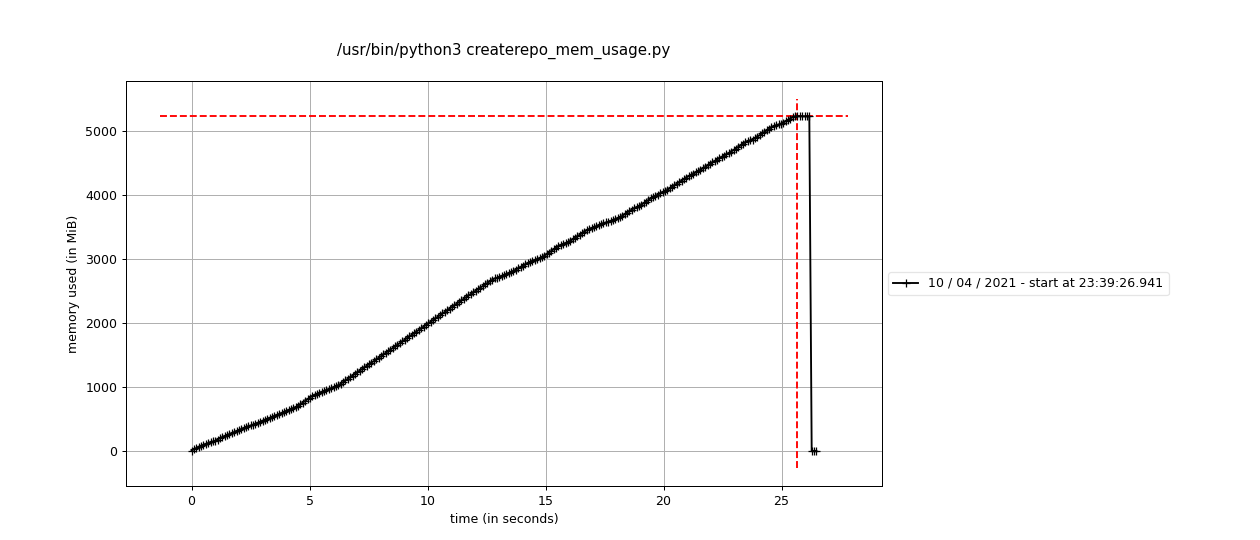
But this baseline doesn't really do anything with the data. Notably, it's all still stored in the C extension at this point. When we pull the data out on the Python side, it gets copied into new Python strings, so it now exists in memory twice (until the Python string gets garbage collected).
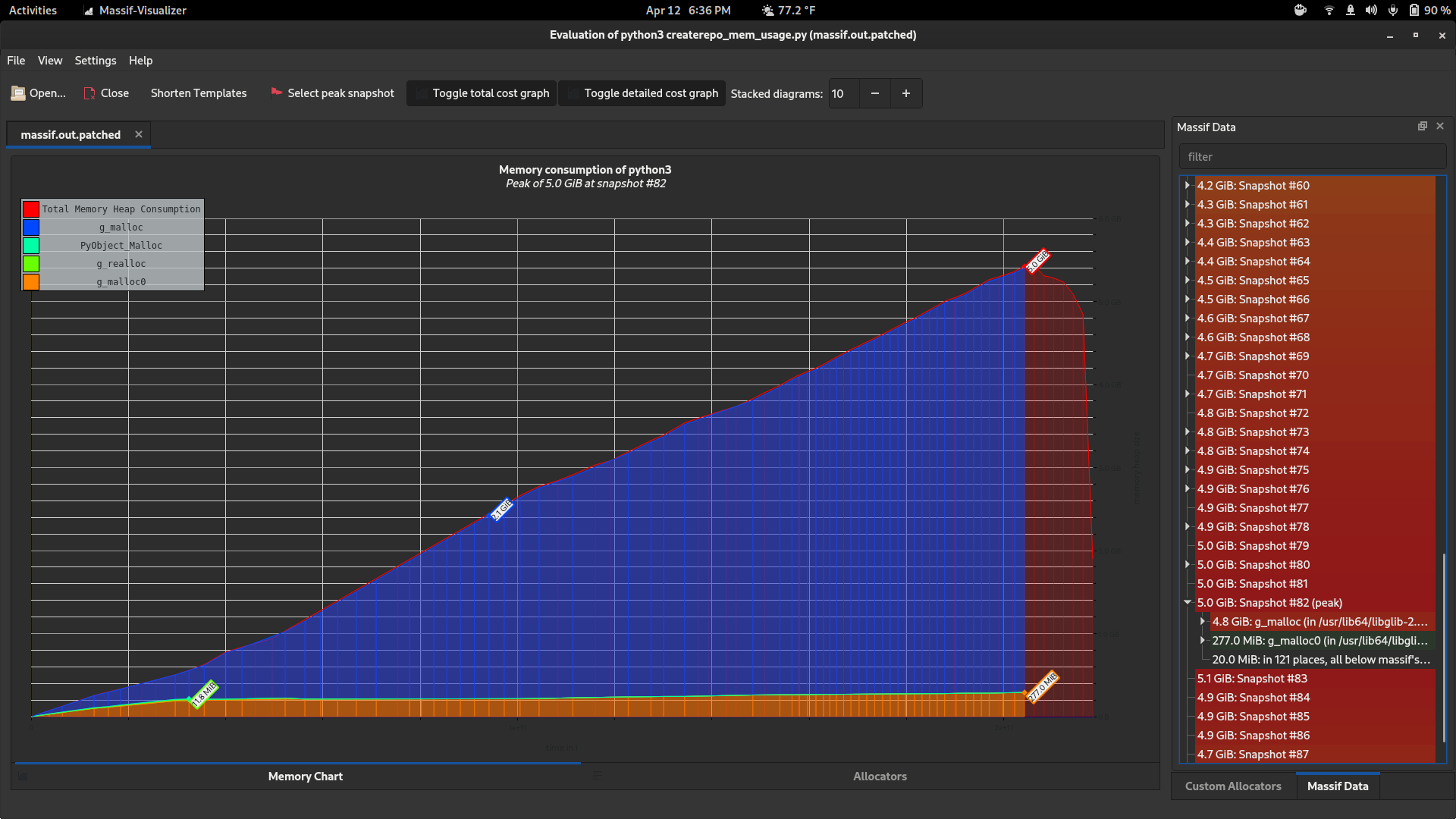
Here's what happens (using the same minimized script) if you parse the repo and then go through all the results and then pull the data out of some of the fields and store it in a list (like we do in the sync pipeline).
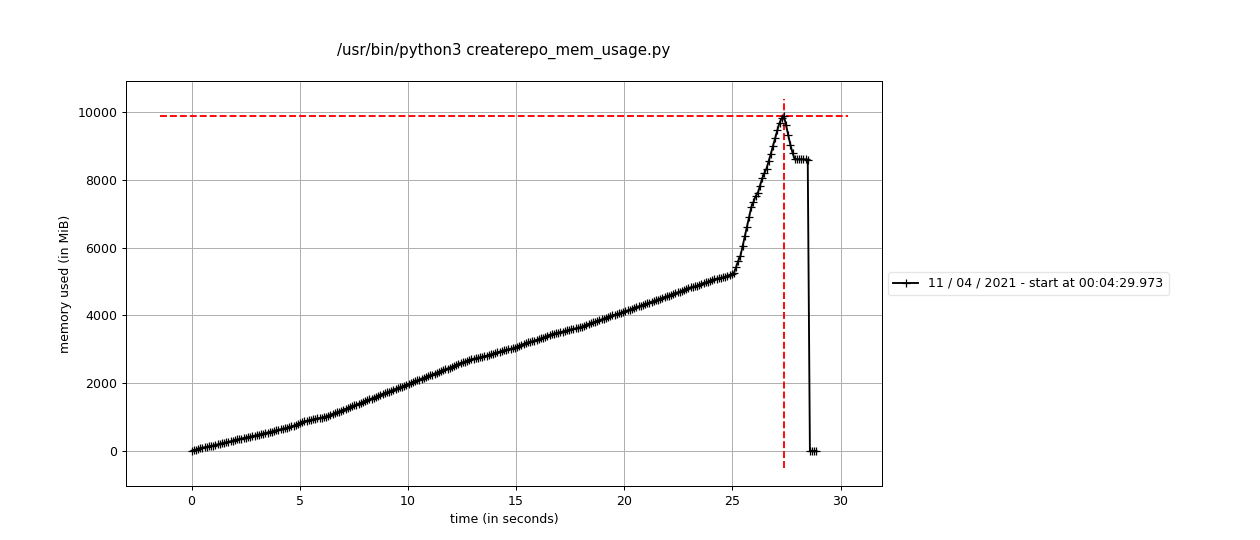
So there's 2 ways to approach minimizing these issues, and I think we should try to do both:
Mitigation 1 is to get rid of the createrepo_c package object as soon as we're done with it, like this:
while True:
try:
# instead of iterating over the dict, we pop items from the dict so that the memory can be freed
# so we go back to only having one copy of the data around - in the form of all of the strings we pull from the package
(_, pkg) = packages.popitem()
except KeyError:
break
do_whatever(pkg)
del pkg # just in case
Here's what that looks like
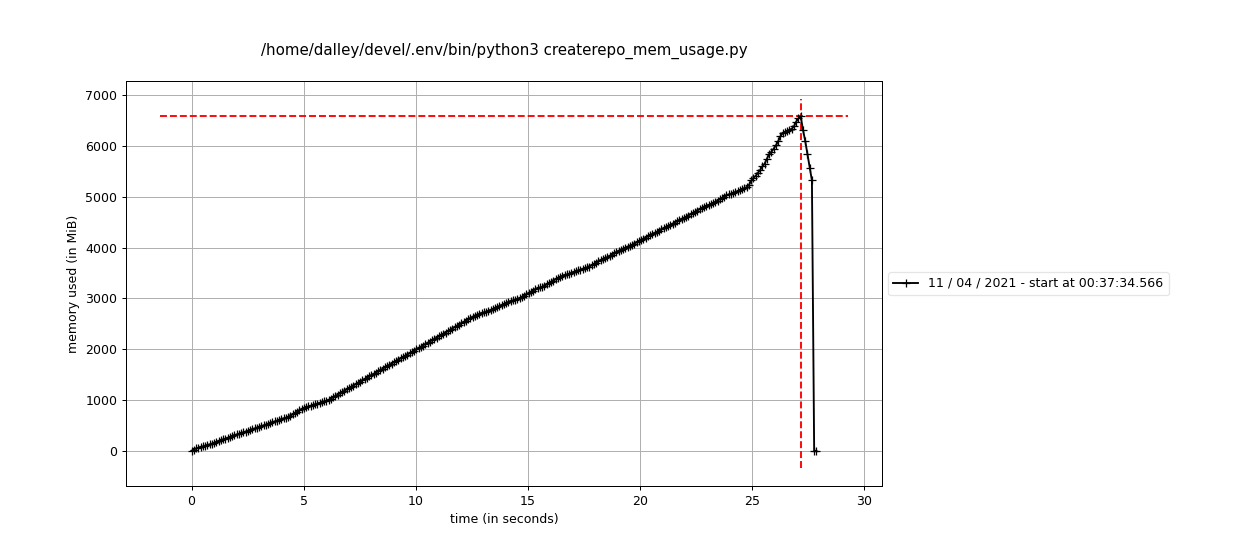
Definitely better. I think we can merge that immediately and re-run the test to see whether that is sufficient for our short-term needs.
Mitigation 2 is that we should take a more comprehensive look at the sync pipeline and make sure we're applying backpressure to the first stage, so that it's not pumping data into the pipeline faster than it can be processed. Because any backups there would result in these kinds of issues (admittedly only for the RPM plugin due to the whole language boundary thing).


{kind=link}
Reduce memory consumption when syncing extremely large repositories
closes: #8467 https://pulp.plan.io/issues/8467