
Issue #1714
closed
Unit copy performance regression in 2.8.
Description
Copying a repository containing 12k units to a new repository takes ~60 seconds. I have bench marked unit query functions in the repository controller and found big performance differences between pymongo and mongoengine. The issue seems related to the hydration of the Document object, not querying the DB.
Files
| Screenshot from 2016-02-25 09-27-46.png (247 KB) Screenshot from 2016-02-25 09-27-46.png | Profile | ||
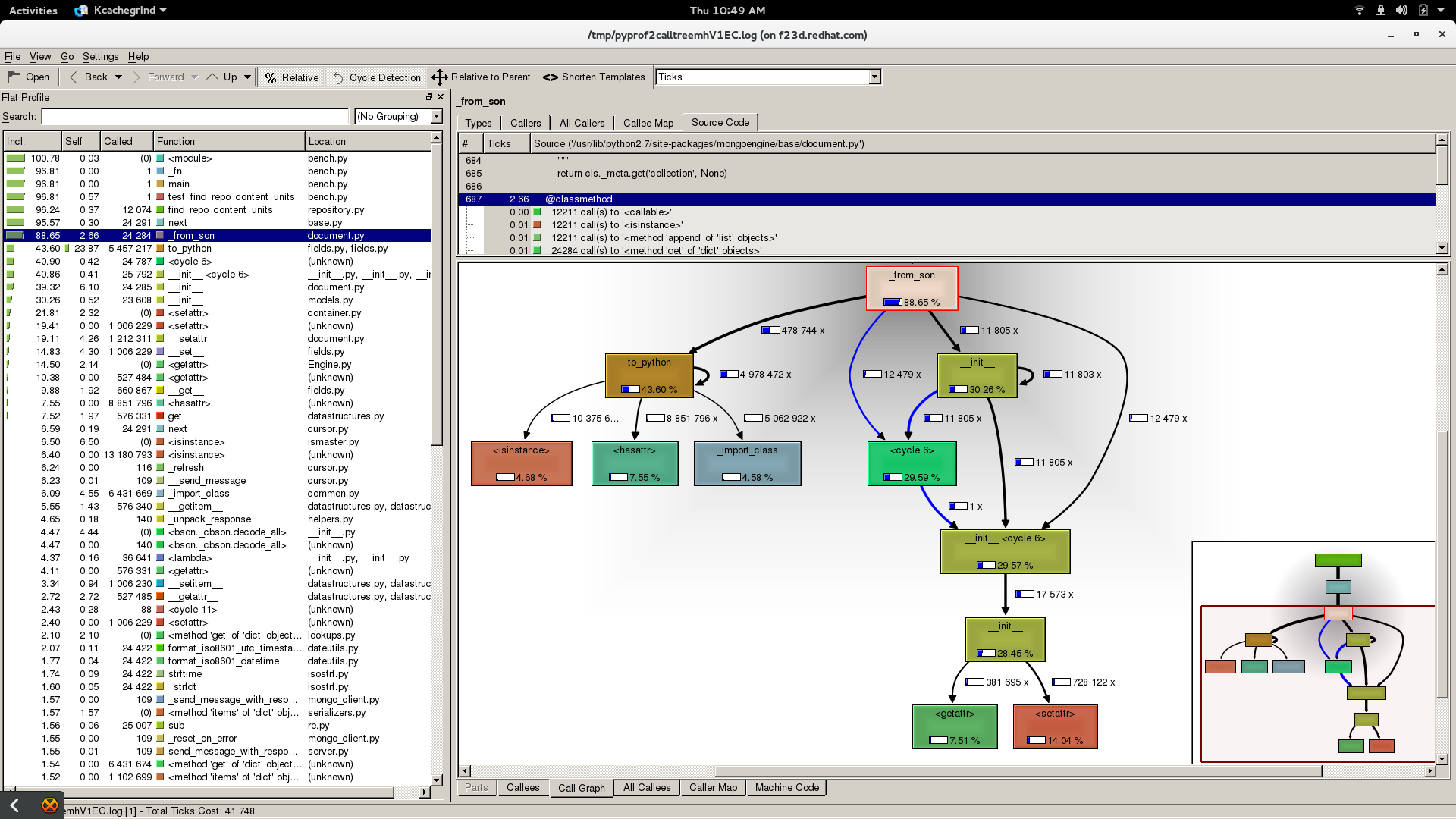
| Screenshot from 2016-02-25 10-49-14.png (319 KB) Screenshot from 2016-02-25 10-49-14.png | Profile find units |
{kind=link}
{kind=link}
 Updated by jortel@redhat.com almost 9 years ago
Updated by jortel@redhat.com almost 9 years ago
Updated by jortel@redhat.com almost 9 years ago
Profiler showing most time spent in Document.__init__() called by Document._from_son() for a test fetching unit associations using pymongo then calling Document._from_son() for each record. Also, this test used a bare bones mongoengine Document subclass instead of the one in the pulp model. The test is intended to isolate the hydration and be free of pulp modeling side effects.

Updated by jortel@redhat.com almost 9 years ago
Updated by jortel@redhat.com almost 9 years ago
Updated by jortel@redhat.com almost 9 years ago
Here we see the profiler statistics if a call to repository.find_repo_content_units(r, yield_content_unit=True).

 Updated by mhrivnak almost 9 years ago
Updated by mhrivnak almost 9 years ago
I did a little related digging. Instantiating RPM model instances, nearly half the time is spent in the to_python() method of ComplexBaseField, which is the parent class for ListField and DictField. Long-term, minimizing the use of those fields could help.
In the mean time, since we probably know the data types to expect inside those structures, we could make our own ListField and DictField subclasses with a custom to_python() that only does the minimum required for the expected data in that specific field. The generic implementation of to_python() does a ton of weak inspection via hasattr, isinstance, try...except with various type-specific operations, and other weird uses of intermediate data structures. Making our own might save a substantial amount of time.
Updated by mhrivnak almost 9 years ago
For this query with about 9100 RPMS:
for x in RPM.objects.filter().only(*RPM.unit_key_fields):
pass
I got the time down from 9.6s to 6.8s just with this patch to mongoengine:
diff --git a/mongoengine/base/document.py b/mongoengine/base/document.py
index 6353162..f6006be 100644
--- a/mongoengine/base/document.py
+++ b/mongoengine/base/document.py
@@ -91,8 +91,8 @@ class BaseDocument(object):
for key, field in self._fields.iteritems():
if self._db_field_map.get(key, key) in __only_fields:
continue
- value = getattr(self, key, None)
- setattr(self, key, value)
+ if not hasattr(self, key):
+ setattr(self, key, None)
if "_cls" not in values:
self._cls = self._class_name
Before running too far with that, we need to ensure there wasn't some reason for mongoengine doing the otherwise strange-looking getattr followed by setattr. But this might be a low-hanging-fruit improvement.
Updated by mhrivnak almost 9 years ago
Before we get too excited, mongoengine's unit test suite isn't very fond of my little optimization. I'll have to dig into why.
FAILED (failures=23, errors=31, skipped=4)
Updated by jortel@redhat.com almost 9 years ago
- Status changed from ASSIGNED to NEW
- Assignee deleted (
jortel@redhat.com)
Updated by jortel@redhat.com almost 9 years ago
- Assignee set to jortel@redhat.com
Fetching 12k RPMs bench marks:
Straight pymongo: 2.5 seconds.
@timed
def test_find_all_rpms_mongo(repo_id=REPO_ID):
total = 0
for rpm in RPM._get_collection().find():
total += 1
print '{0} PRMs found'.format(total)
Using generic Unit class: 3.0 seconds.
The goal was to see just how fast a light weight object could be constructed.
@timed
class Unit(object):
def __init__(self, fields, data):
attributes = {}
for name, field in fields.items():
key = field.db_field or name
value = data.get(key, field.default)
if not isinstance(field, (StringField, ListField, DictField)):
value = field.to_python(value)
attributes[name] = value
self.__dict__.update(attributes)
def test_find_all_rpms_light(repo_id=REPO_ID):
total = 0
fields = RPM._fields
for data in RPM._get_collection().find():
unit = Unit(fields, data)
print '{0} PRMs found'.format(total)
Fetching using mongoengine with as_pymongo(): 7 seconds.
@timed
def test_find_all_rpms_as_pymongo(repo_id=REPO_ID):
total = 0
for rpm in RPM.objects.as_pymongo():
total += 1
print '{0} PRMs found'.format(total)
Fetched with mongoengine with RPM.__init__() overridden: 15 seconds.
This is interesting because it suggests that the mechanism for constructing the concrete Document class adds significant overhead. Some of this can be attributed to _from_son().
class RPM(RpmBase):
...
def __init__(self, **kwargs):
self.__dict__.update(kwargs)
...
Fetched with mongoengine: 24 seconds.
 Updated by semyers almost 9 years ago
Updated by semyers almost 9 years ago
- Platform Release changed from 2.8.1 to 2.8.2
Updated by mhrivnak almost 9 years ago
- Status changed from NEW to ASSIGNED
- Assignee changed from jortel@redhat.com to mhrivnak
Updated by mhrivnak almost 9 years ago
I did some testing of pulp 2.6.5, 2.7.1, and 2.8.1-rc. I created a centos7 VM with 2.6.5 and sync'd a base rhel7 repo, with 4620 packages. I then created two copies of the VM, and upgraded them to 2.7.1 and 2.8.1-rc respectively.
Hardware was a 4-year-old desktop machine with a single spinning disk that's rather slow.
On each VM I copied all rpms from the rhel7 repo into a new repo. I did this three times and calculated the average time:
2.6.5: 16.17s
2.7.1: 20.35s
2.8.1: 34.24s
Since I was doing orphan purges between tests anyway, I gathered times on that operation also:
2.6.5: 2.47s
2.7.1: 2.84s
2.8.1: 10.15s
The big jump on 2.8.x is mostly due to using mongoengine. We've discovered that instantiating mongoengine classes is a surprisingly expensive operation. Part of the copy performance jump also may be due to new behavior that guards against duplicate NEVRA in a repo, but I am only speculating on this: https://pulp.plan.io/issues/1461
I don't know why 2.7.1 is 25% slower than 2.6.5.
Updated by semyers almost 9 years ago
- Platform Release changed from 2.8.2 to 2.8.3
Updated by semyers almost 9 years ago
- Platform Release changed from 2.8.3 to 2.8.4
Updated by mhrivnak almost 9 years ago
- Platform Release deleted (
2.8.4) - Triaged changed from Yes to No
 Updated by dkliban@redhat.com almost 9 years ago
Updated by dkliban@redhat.com almost 9 years ago
- Priority changed from High to Normal
- Severity changed from 2. Medium to 1. Low
Updated by dkliban@redhat.com almost 9 years ago
- Triaged changed from No to Yes
Updated by mhrivnak over 8 years ago
- Status changed from ASSIGNED to CLOSED - WONTFIX
Lacking any promising options for reversing the regression in the near term, we will close this for now. We anticipate that moving to postgres is very likely to yield improved performance.